Zhengxue Cheng
Shanghai Jiao Tong University

I am currently an assistant researcher at MediaLab, in Shanghai Jiao Tong University, working with Prof. Wenjun Zhang, Prof. Li Song. Before that, I received the B.E. degree from Shanghai Jiao Tong University in 2014 and double M.E. degrees from Waseda University and Shanghai Jiao Tong University in 2015 and 2017, respectively. I received a PhD.degree at Waseda University in 2020 under the supervision of Prof. Jiro Katto. From 2018 to 2019, I was a visiting intern at EPFL, Switzerland, working with Prof. Touradj Ebrahimi. After that I worked in Ant Group, Hangzhou, China, as an Algorithm Expert until April 2024.
My research interests include deep learning-based multimodal data compression, image and video enhancement, and lightweight AI algorithm designs. I also received the JSPS DC2, Okawa Foundation Research Grant 2024, CVPR NTIRE 2025 Effficient Super Resolution Winner, VCIP 2024 Best Student Paper RunnerUp, VCIP 2025 Best Paper, PCS 2019 Silver Award for Grand Challenge.
For prospective students interested in AI or data coding, feel free to contact me via email!
news
| Dec 05, 2025 | Our Paper AlignGS received the VCIP 2025 Best Paper. |
|---|---|
| Oct 22, 2025 | I will serve as an AE of IEEE TCSVT. |
selected publications
-
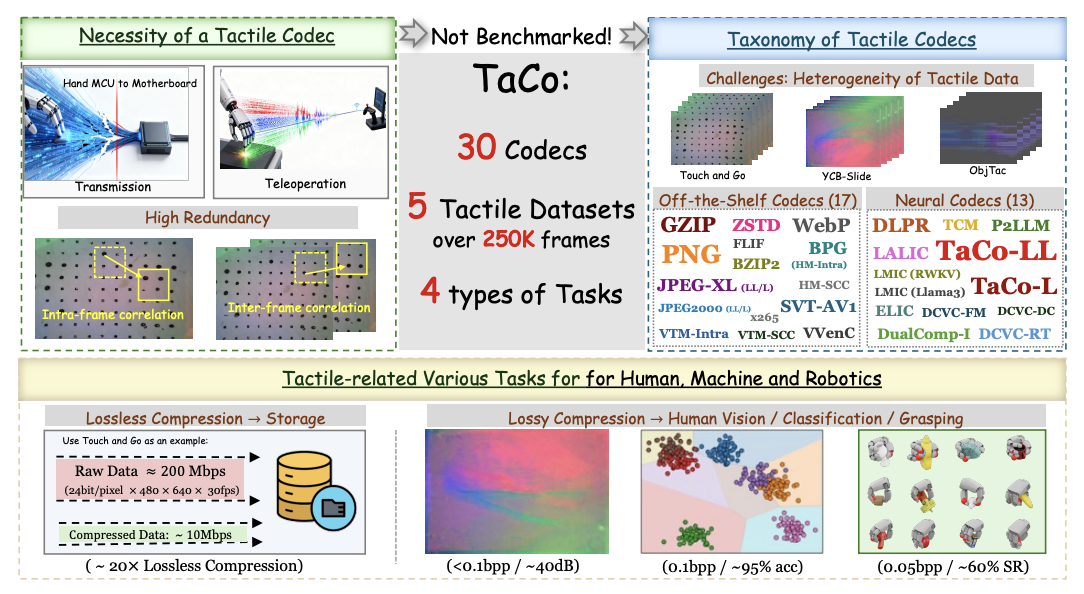 TaCo: A Benchmark for Lossless and Lossy Codecs of Heterogeneous Tactile DataIn International Conference on Learning Representations (ICLR), 2026
TaCo: A Benchmark for Lossless and Lossy Codecs of Heterogeneous Tactile DataIn International Conference on Learning Representations (ICLR), 2026 -
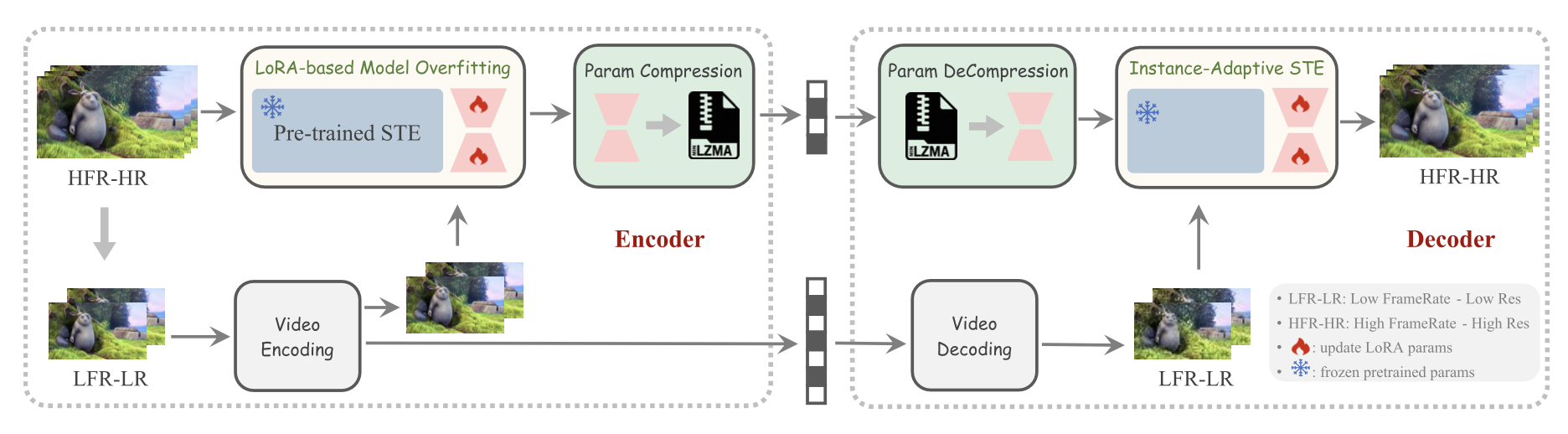 Instance-Adaptive Spatial-Temporal Enhancement for Efficient Video CompressionIEEE Trans. on Image Processing, 2025
Instance-Adaptive Spatial-Temporal Enhancement for Efficient Video CompressionIEEE Trans. on Image Processing, 2025 -
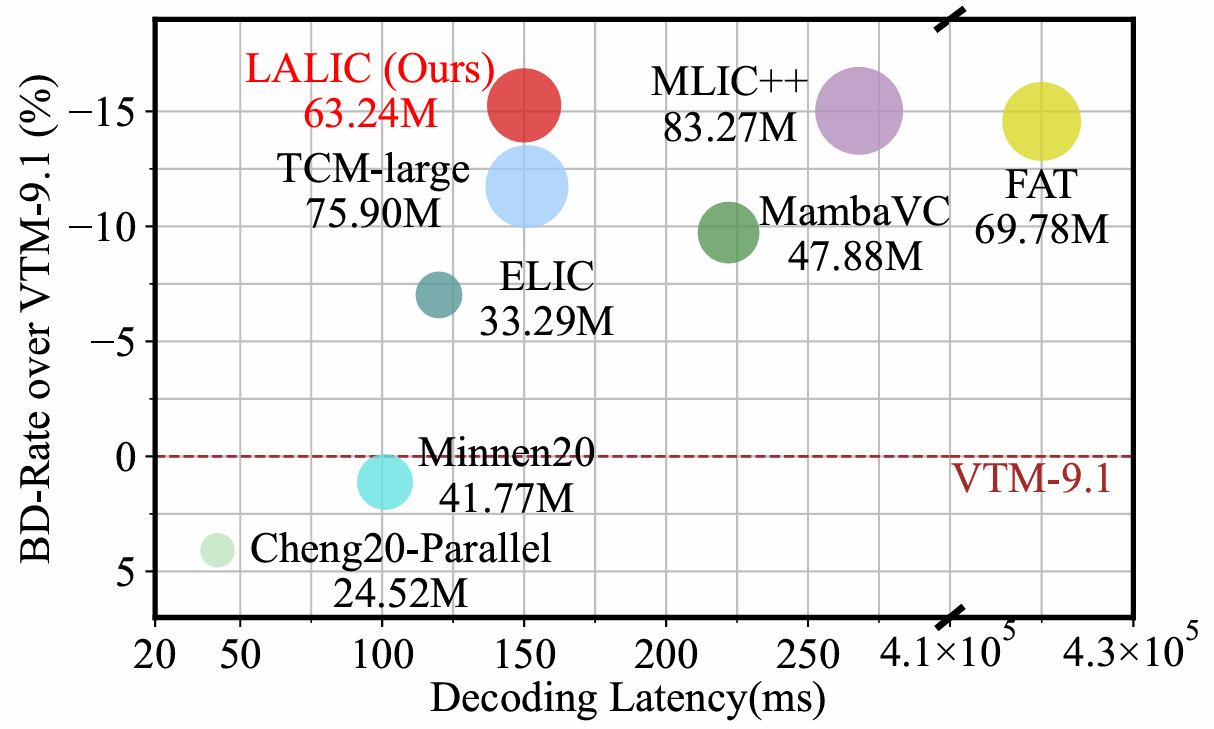 Linear Attention Modeling for Learned Image CompressionIn Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), Jun 2025
Linear Attention Modeling for Learned Image CompressionIn Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), Jun 2025 -
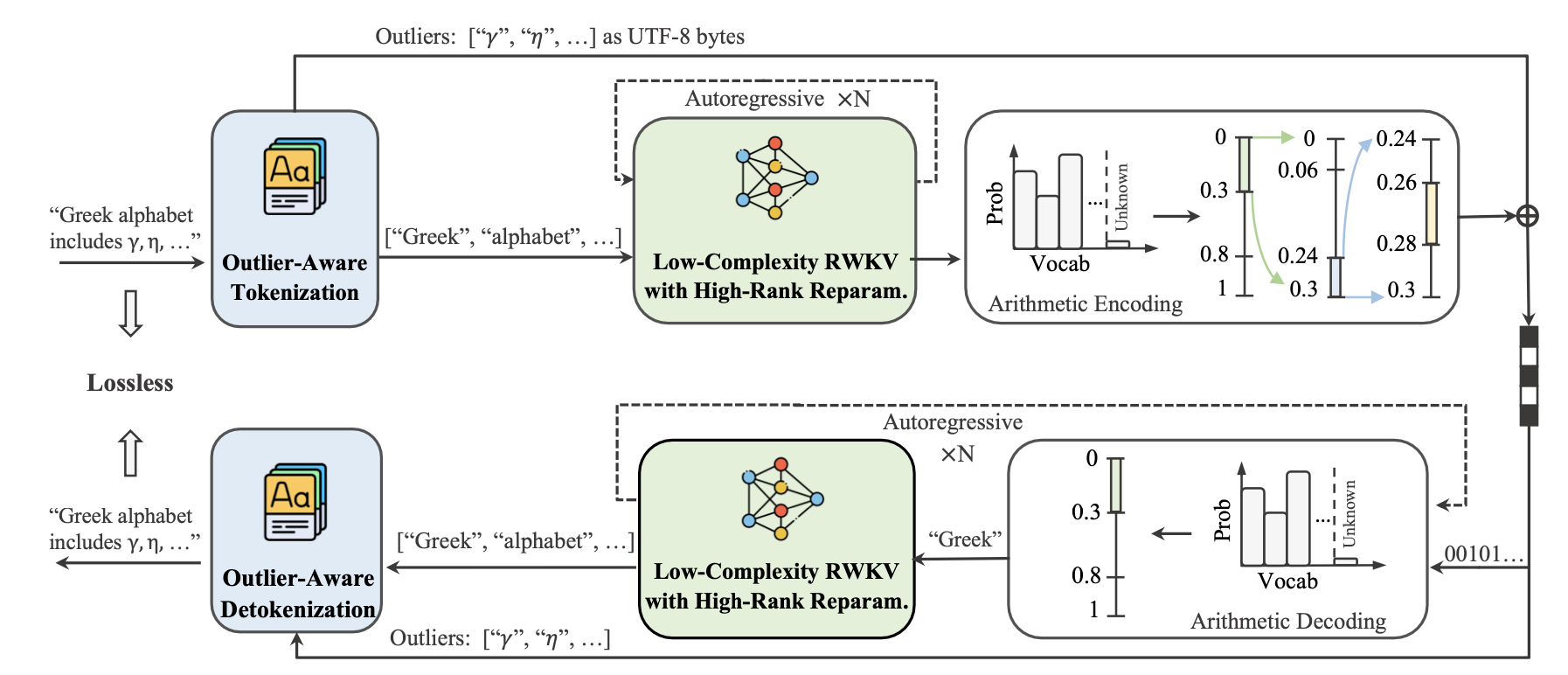 L3TC: leveraging RWKV for learned lossless low-complexity text compressionIn Proceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence, Jun 2025
L3TC: leveraging RWKV for learned lossless low-complexity text compressionIn Proceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence, Jun 2025 -
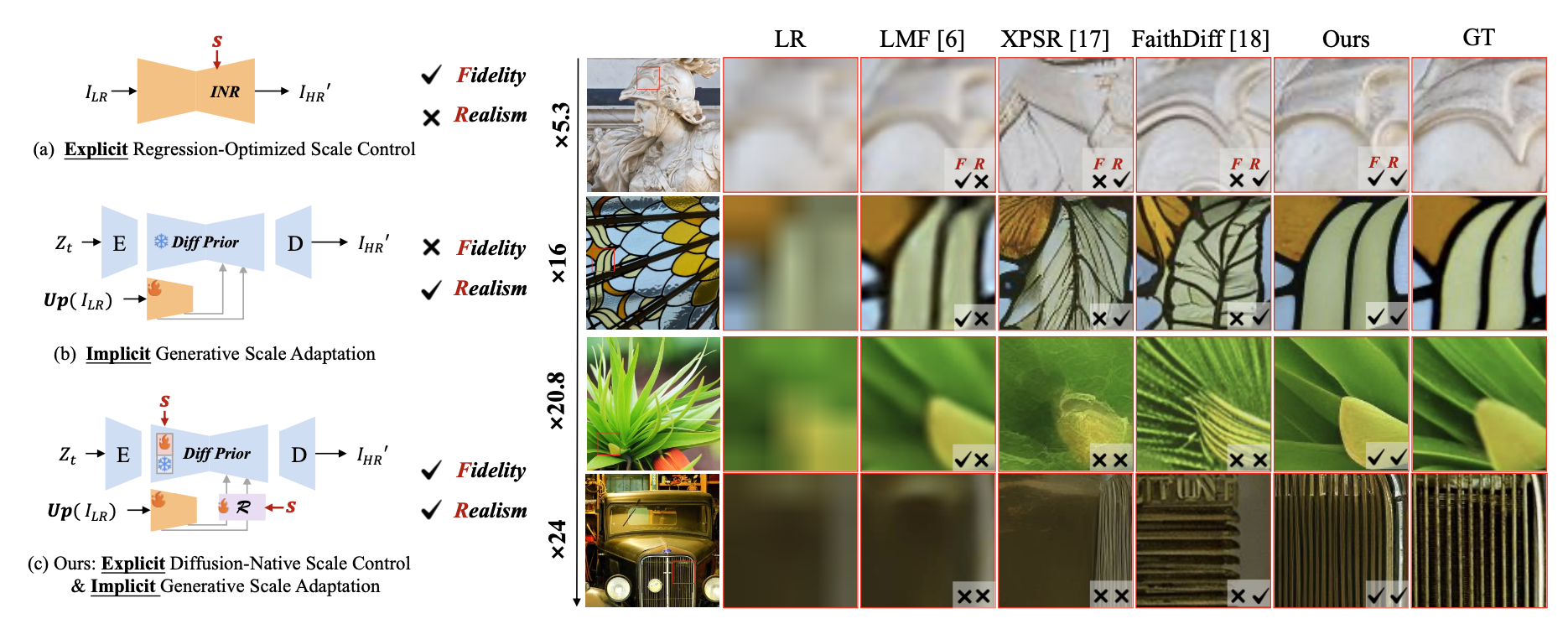 OmniScaleSR: Unleashing Scale-Controlled Diffusion Prior for Faithful and Realistic Arbitrary-Scale Image Super-ResolutionIEEE Transactions on Circuits and Systems for Video Technology, Jun 2025
OmniScaleSR: Unleashing Scale-Controlled Diffusion Prior for Faithful and Realistic Arbitrary-Scale Image Super-ResolutionIEEE Transactions on Circuits and Systems for Video Technology, Jun 2025 -
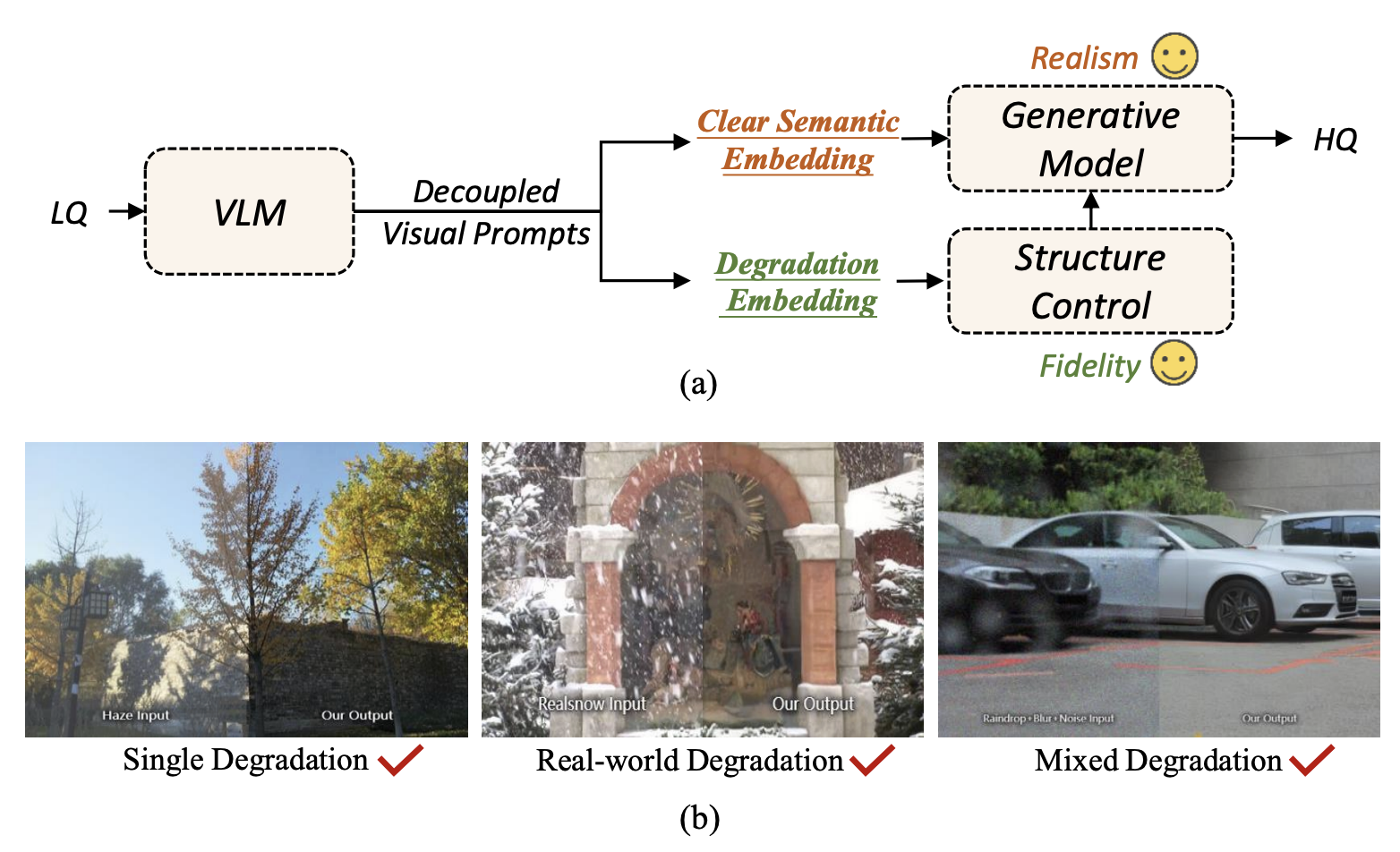 Diff-Restorer: Unleashing Visual Prompts for Diffusion-based Universal Image RestorationIEEE Transactions on Circuits and Systems for Video Technology, Jun 2025
Diff-Restorer: Unleashing Visual Prompts for Diffusion-based Universal Image RestorationIEEE Transactions on Circuits and Systems for Video Technology, Jun 2025 -
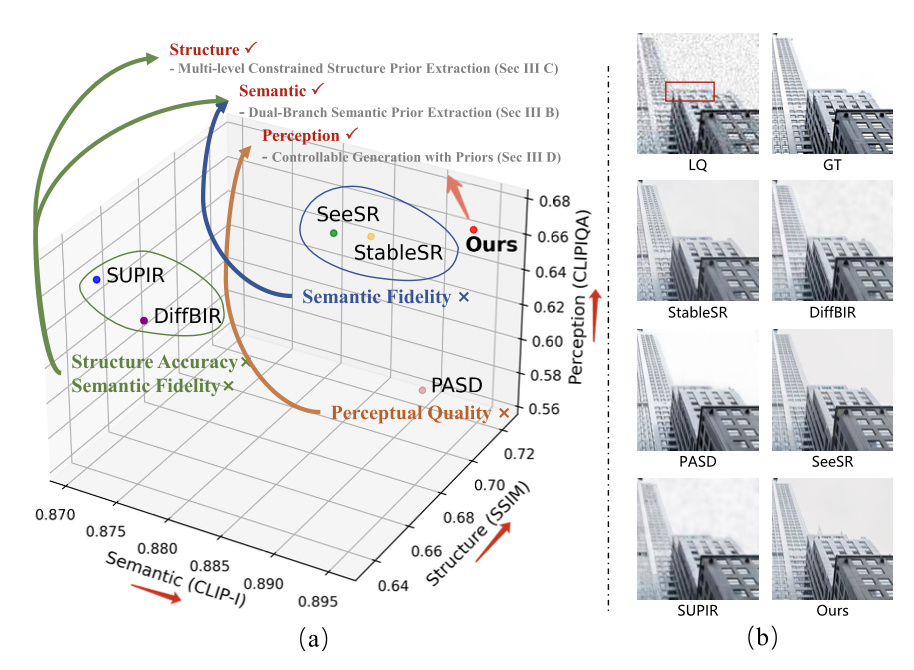 SSP-IR: Semantic and Structure Priors for Diffusion-Based Realistic Image RestorationIEEE Transactions on Circuits and Systems for Video Technology, Jun 2025
SSP-IR: Semantic and Structure Priors for Diffusion-Based Realistic Image RestorationIEEE Transactions on Circuits and Systems for Video Technology, Jun 2025 -
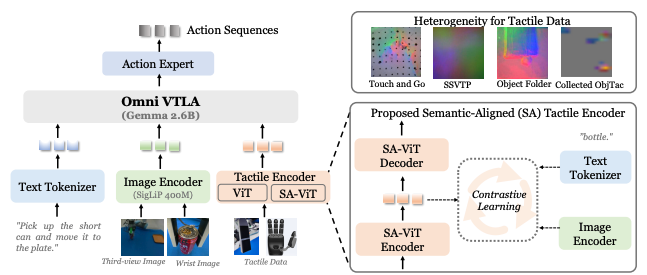 OmniVTLA: Vision-Tactile-Language-Action Model with Semantic-Aligned Tactile SensingJun 2025
OmniVTLA: Vision-Tactile-Language-Action Model with Semantic-Aligned Tactile SensingJun 2025 -
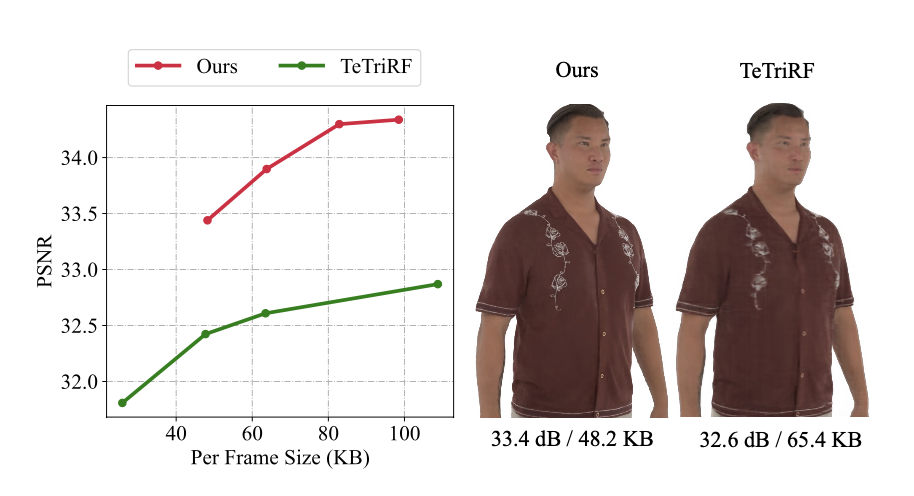 Rate-aware Compression for NeRF-based Volumetric VideoIn Proceedings of the 32nd ACM International Conference on Multimedia, Melbourne VIC, Australia, Jun 2024
Rate-aware Compression for NeRF-based Volumetric VideoIn Proceedings of the 32nd ACM International Conference on Multimedia, Melbourne VIC, Australia, Jun 2024
